Abstract
In this work, we incentivize gamers to share their gaming experience on social media by automatically generating eye-catching highlight clips from their gameplay session. We approach the highlight generation problem by first identifying intervals in the video where interesting events occur and then concatenating them. We develop an in-house gameplay event detection dataset containing interesting events annotated by humans using VIA video annotator [1] [2]. We finetune a general purpose video understanding model such as X-CLIP [3] using our dataset. Prompt engineering was performed to improve the classification performance of this multimodal model. Our evaluation shows that such a finetuned model can detect interesting events in first person shooting games from unseen gameplay footage with more than 90% accuracy. We also finetuned a video encoder model such as VideoMAE [4]. However, only the final classification layer could be finetuned while keeping the encoder weights frozen. This was done to prevent overfitting due to the small size of our dataset. To conclude, we show that natural language supervision leads to data efficient video recognition models
Moreover, our model performed significantly better on low resource games (games with small dataset of annotated videos) when finetuned along with high resource games, thus, showing signs of transfer learning. We used ONNX libraries [6] to enable efficient cross platform inference. These libraries contain post training quantization APIs which reduce model size for efficient inference. The DirectML backend inference engine for ONNX enabled efficient deployment on Windows which enabled background inference with minimal impact on FPS while gaming.
Images
X-CLIP results
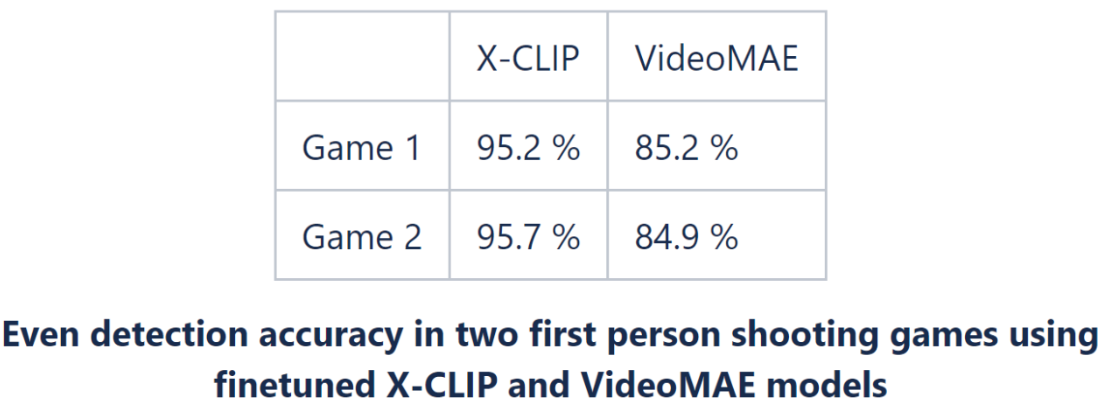
VideoMAE results
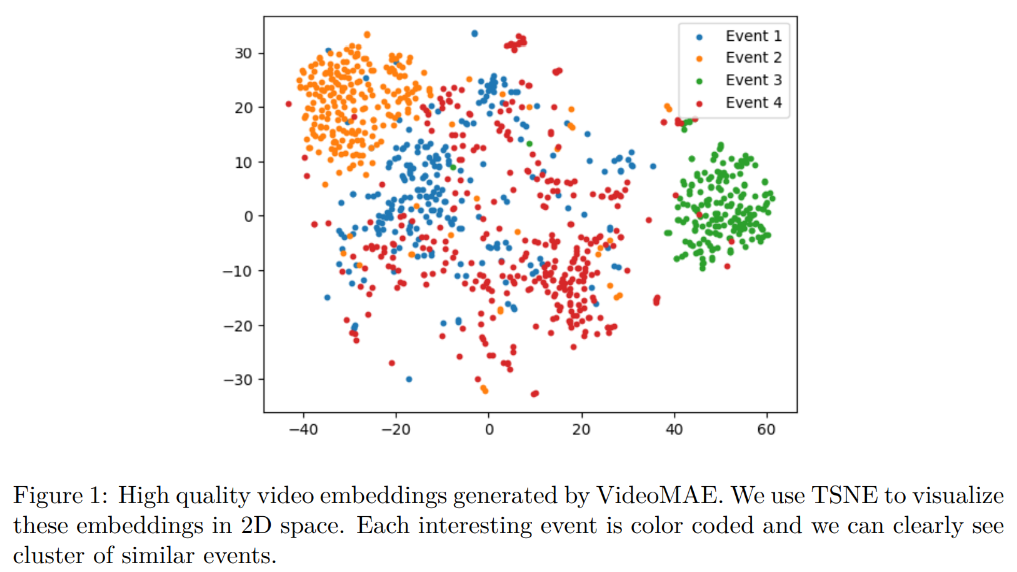
Dataset distribution
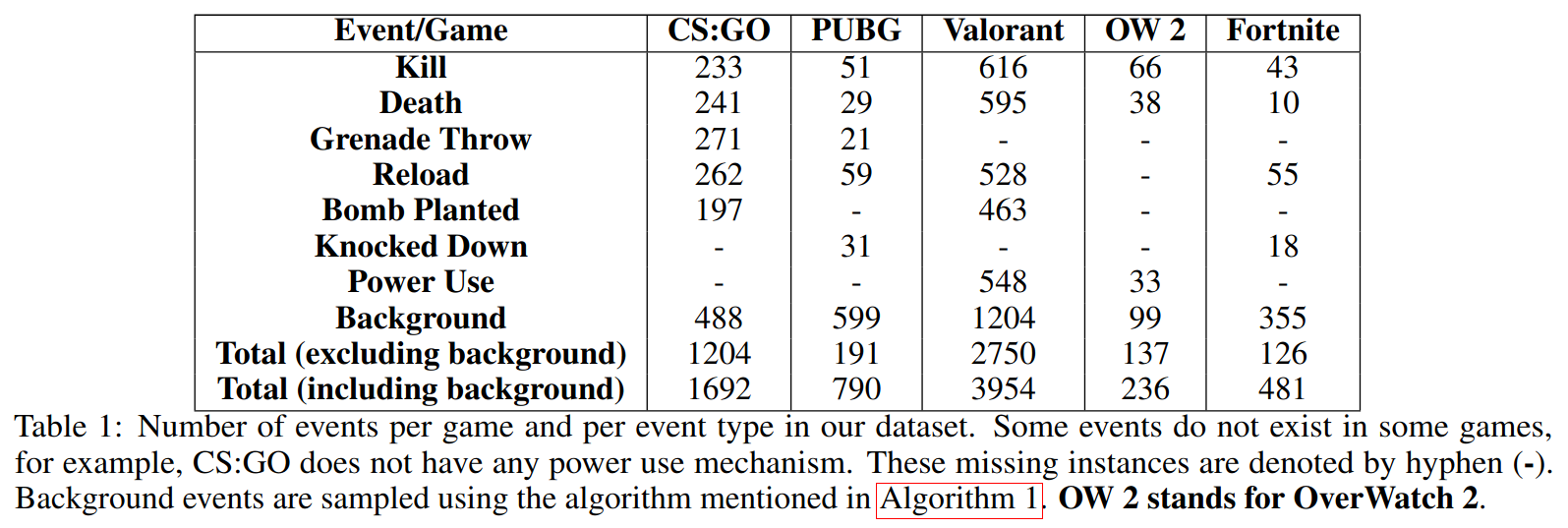
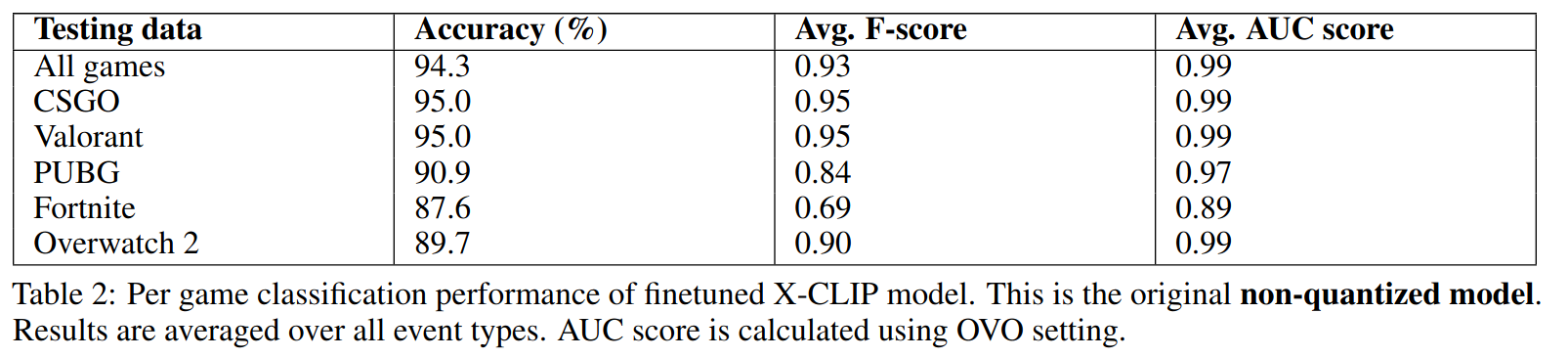
Testing results
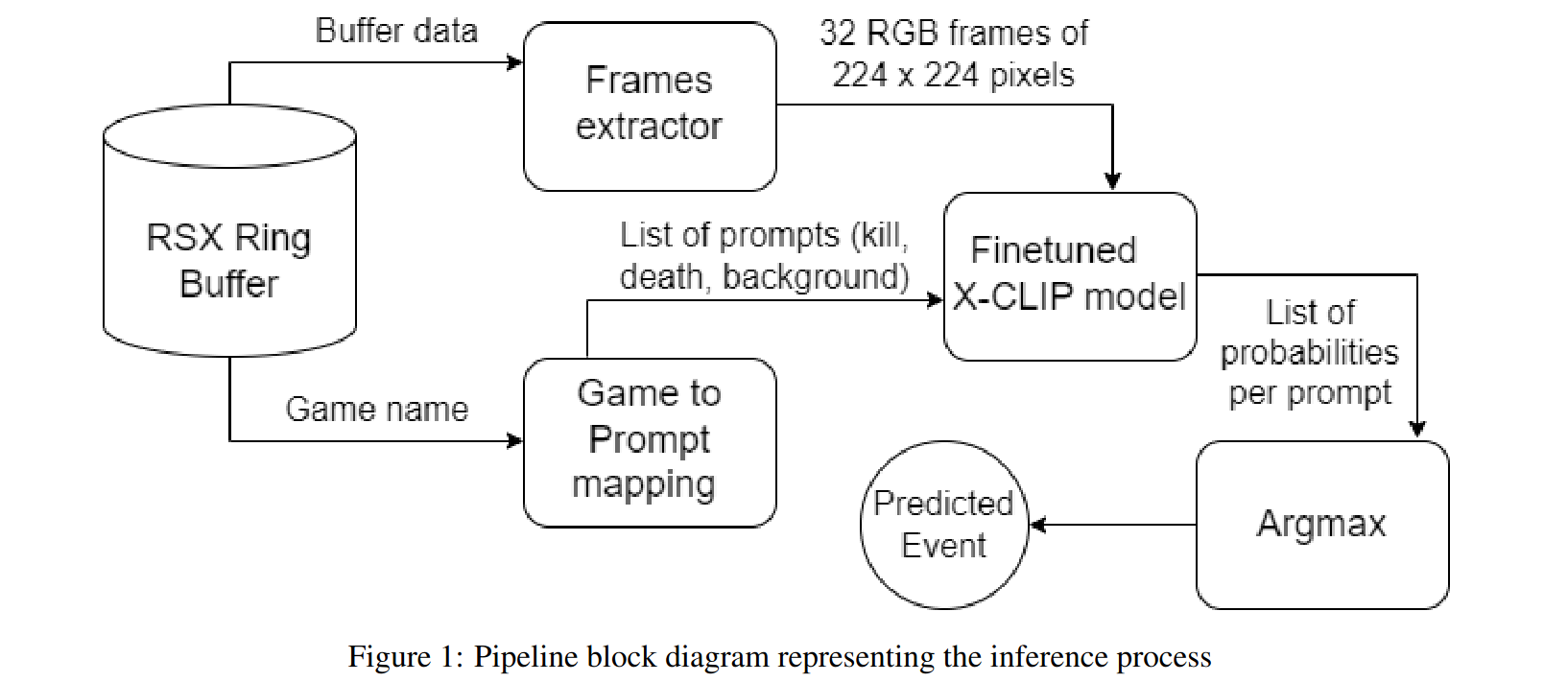
Training pipeline
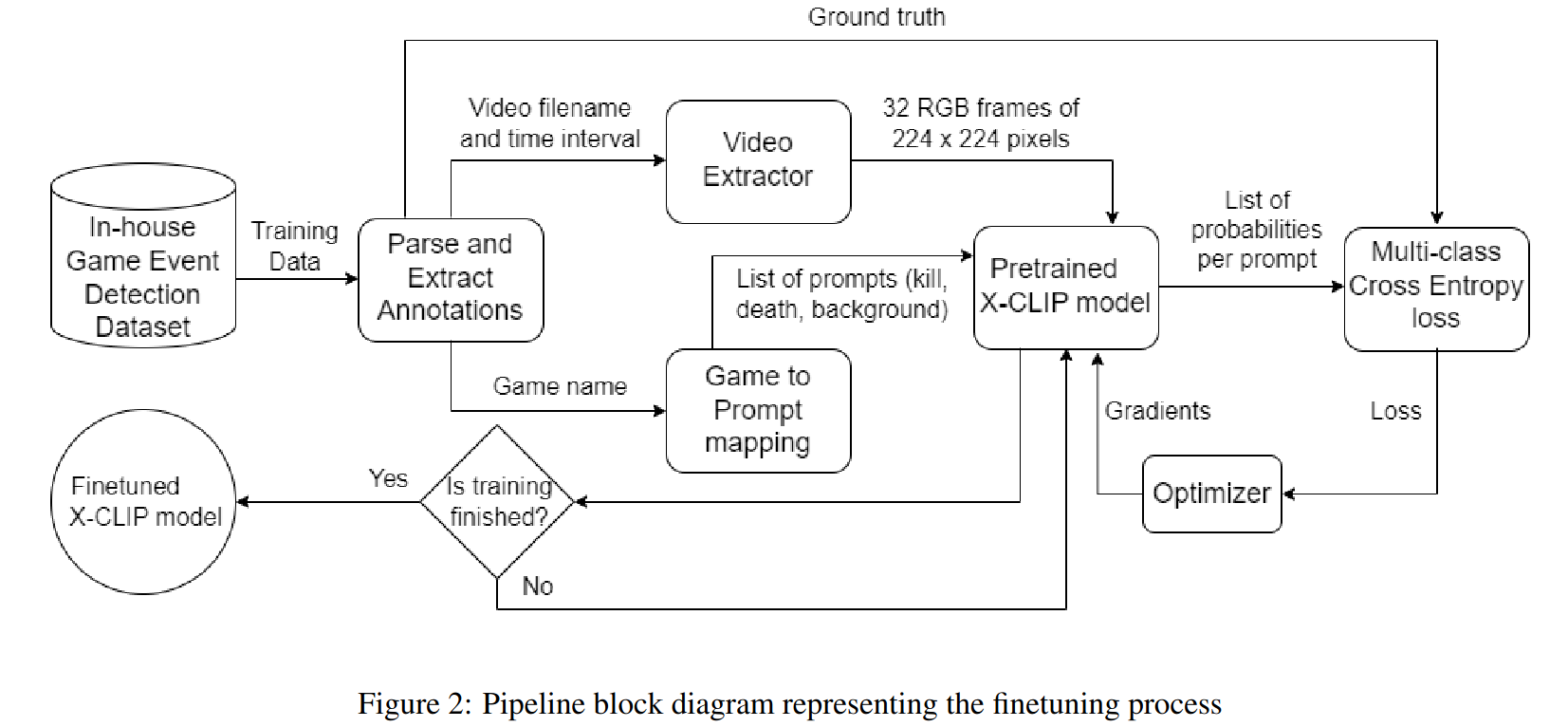
Inference pipeline
Acknowledgements
All credits for this work goes to the authors of this paper [5]
Link to research report
Click here to see the research report uploaded to arxiv
References
[1] A. Dutta, A. Gupta, and A. Zissermann. VGG image annotator (VIA), 2016. Version: 3.0.12, Accessed: 24 August 2023.
[2] Abhishek Dutta and Andrew Zisserman. The VIA annotation software for images, audio and video. In Proceedings of the 27th ACM International Conference on Multimedia, MM ’19, New York, NY, USA, 2019. ACM.
[3] Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition, 2022.
[4] Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training, 2022.
[5] https://arxiv.org/abs/2505.07721
[6] https://onnx.ai/onnx/intro